Exploring Advancements in Large Language Model deployment: Skypilot, vLLM and Ngrok
Introduction
In the ever-evolving landscape of artificial intelligence, deploying Large Language Models (LLMs) effectively is a challenge that organizations can't afford to overlook. This post serves a dual purpose: to help you understand the unique challenges involved in LLM deployment and to explore cutting-edge tools like SkyPilot, Ray, and vLLM that can dramatically simplify this complex task.
Part 1: LLM Deployment: The Startup's Quandary and the Enterprise's Conundrum
The Importance of LLM Ops
The buzz in the AI world may often be about new algorithms and fascinating use-cases, but the reality of turning that algorithmic promise into functional applications lies in operations — specifically Large Language Model Operations (LLM Ops). For startups, this means not just cracking the AI code but also delivering it in a scalable, efficient manner. The stakes are just as high for enterprises but scaled up manifold. Each inefficiency is amplified, and each operational hurdle could translate into significant financial implications.
Challenges in Deploying LLMs: A Startup Perspective
Deploying LLMs is a venture rife with challenges, more so for startups that are already juggling resources and timelines. Some of the hurdles that must be overcome include:
-
Massive Checkpoint Size: Storing and managing the large checkpoints of these models require a robust storage solution. This can mean higher costs and more complex infrastructure pipelines.
-
GPU Cost and Availability: The hardware demands of LLMs often require top-of-the-line GPUs. For a team with limited funds, this becomes a significant barrier to entry. Even for those who can afford it, GPU availability can be a logistical nightmare.
-
Complexity in Underlying Libraries: Startups usually don't have the luxury of dedicated teams to manage the intricacies of libraries like PyTorch and Transformers. A single misconfiguration can result in days of debugging, affecting the company's agility.
The Enterprise Parallel
Enterprises face these challenges too, but on an expenontially larger scale. Let’s take GPU costs as an example. An enterprise deployment might require a data center full of GPUs, with the costs scaling up proportionally. The complexity of underlying libraries? Imagine coordinating across multiple departments and perhaps even geographical locations to troubleshoot issues.
The Common Ground
Whether you're a startup aiming to break into the market or an enterprise looking to scale up, the challenges of LLM deployment are largely similar but differ in scale. In both scenarios, addressing these challenges requires deep knowledge of both the AI models involved and the operational complexities.
Mapping LLMs to Traditional and Cutting-Edge Infrastructures
While the challenges of LLM deployment may appear daunting, there's an encouraging silver lining. Traditional cloud infrastructure can often provide a foundation upon which these complex models can be deployed. Technologies like Docker have played a significant role in this, acting as a bridge between the intricate realm of machine learning and the more universally understood sphere of cloud computing.
Yet, the field is far from static. Groundbreaking work is being done to make these deployments even more accessible and efficient. Programs like UC Berkeley’s Sky Computing Lab are at the forefront of these advancements, pushing the boundaries of what's possible in machine learning operations and cloud-based AI workloads. It's no longer just about fitting machine learning into existing paradigms; it's about creating new paradigms altogether to make AI and machine learning more accessible, scalable, and efficient.
Part 2: Fast-Tracking LLM Deployment with SkyPilot and Ray
The fast-paced evolution of deploying large language models (LLMs) and AI workloads can be challenging to navigate. SkyPilot and Ray serve as guiding stars in this transformative journey, working together to simplify the complexities of cloud-based deployment.
SkyPilot: Your All-In-One Hub for Cloud-Optimized AI Deployment
SkyPilot isn't just another tool—it's an entire ecosystem built to democratize the deployment of LLMs and various AI workloads. With compatibility across a vast array of cloud providers, SkyPilot ensures that you're never locked into a single service.
Why Choose SkyPilot?
-
Simplified Cloud Management: Forget the intricate details of cloud architecture. SkyPilot's cloud abstraction feature allows you to launch jobs and clusters on any provider with ease.
-
Automated Task Handling: Queuing multiple jobs or tasks? SkyPilot takes care of that, leaving you free to focus on fine-tuning your AI models.
-
Cost-Effectiveness: Get the most out of your investment with features like Managed Spot and an Optimizer, both designed to reduce your operational costs.
-
Versatile Workload Integration: SkyPilot integrates effortlessly with your existing computational workloads, streamlining migration and reducing friction.
Ray: The Bedrock of SkyPilot
Underpinning SkyPilot's capabilities is Ray, an open-source framework that specializes in scalable computing. Ray is designed to be the backbone for a diverse range of AI and Python applications.
Why Ray Stands Out:
-
Efficient Distributed Computing: Accelerate your deep learning tasks with Ray's robust execution framework, compatible with PyTorch and TensorFlow.
-
Optimized Hyperparameter Tuning: Ray Tune employs state-of-the-art optimization techniques, speeding up your search for the best model parameters.
-
Streamlined Model Serving: Ray Serve makes deploying ML models at scale easy and hassle-free, serving as a Python-first and framework-agnostic option.
-
Reinforcement Learning at Scale: Utilize Ray's RLlib to scale your reinforcement learning workloads, with support for a multitude of leading-edge algorithms.
SkyPilot and Ray jointly serve as the vanguards in the changing landscape of LLM and AI deployment, making it easier, more cost-effective, and agile.
Part 3: Speeding Up Inference with vLLM
As we resolve the challenges of infrastructure orchestration, the focus shifts to enhancing inference speed. Enter vLLM, an open-source library that sets new benchmarks for LLM throughput, developed by a team at UC Berkeley and already deployed in platforms like Chatbot Arena and Vicuna Demo.
vLLM: The New Standard in LLM Serving
vLLM aims to overcome the conventional bottlenecks in LLM inference, namely limited speed and resource constraints. It introduces an innovative attention algorithm called PagedAttention, capable of dramatically boosting throughput without altering existing model architectures.
Why vLLM Changes the Game:
-
Peerless Throughput: vLLM shatters previous records, outperforming even the popular HuggingFace Transformers library by up to 24x in throughput metrics.
-
Resource Conservation: With vLLM, even smaller teams with constrained resources can perform LLM serving efficiently.
PagedAttention: The Catalyst Behind vLLM
The ingenuity of vLLM rests in its groundbreaking PagedAttention algorithm, designed to optimize memory management and performance.
What Makes PagedAttention Unique:
-
Memory Efficiency: PagedAttention subdivides the memory cache into blocks, dramatically cutting down memory waste and improving hardware utilization.
-
High Throughput: Better memory management enables greater sequence batching, thus enhancing GPU utilization and overall throughput.
-
Adaptive Scalability: PagedAttention adjusts its performance based on variable sequence lengths, ensuring optimal resource utilization.
The Road Ahead
vLLM and PagedAttention signify a monumental shift towards faster, more efficient LLM serving. The open-source nature and ease of deployment make vLLM an indispensable tool for anyone looking to optimize their LLM operations. For a deep dive into the technology, check out vLLM's GitHub repository, with a comprehensive academic paper coming soon.
Part 4: Running vLLM on Spot Instances with SkyPilot
Introduction
Running machine learning models like vLLM on spot instances can significantly cut costs, but poses unique challenges in terms of request routing and instance management. SkyPilot and ngrok compose together nicely to make this process seamless. In this section, we'll explore how SkyPilot manages your spot instances and how ngrok solves the complexities of routing requests to a fluid set of servers located across the globe.
The Constraints of Using SkyPilot Spot
While SkyPilot excels at managing spot instances, it's worth noting that it doesn't (yet) handle the complexities of routing requests to these ephemeral APIs. Initialization and termination latencies can be a bottleneck, particularly for time-sensitive workloads.
Why ngrok Edge Rocks
When you're dealing with distributed sets of inference servers, ngrok's Cloud Edge is your secret weapon. It simplifies the request-routing puzzle by directing traffic to the most appropriate server based on geography, load, and availability. The best part? You get this robust, secure, and scalable routing without changing a single line of code.
ngrok Features Simplified
-
Custom Subdomains: Make your service easily identifiable without buying a new domain.
-
Access Control: Implement robust security with OAuth 2.0 and Single Sign-On options.
-
Encryption: Benefit from best-in-class HTTPS/TLS Certificates for secure connections.
-
Observability: Get real-time insights with integrated traffic logging.
Pairing SkyPilot and ngrok brings you the best of both worlds. While SkyPilot manages the ever-changing landscape of your spot instances, ngrok ensures your requests are securely and efficiently routed. In the next section, we'll delve into the step-by-step setup of this cost-efficient and streamlined architecture.
Part 5: Step-by-Step Implementation Guide
In this section, we'll walk through the process of setting up and deploying your SkyPilot job using vLLM and Ngrok. We will also touch on how to use the inference endpoint.
Our goal is to get something deployed that ultimately looks like this:
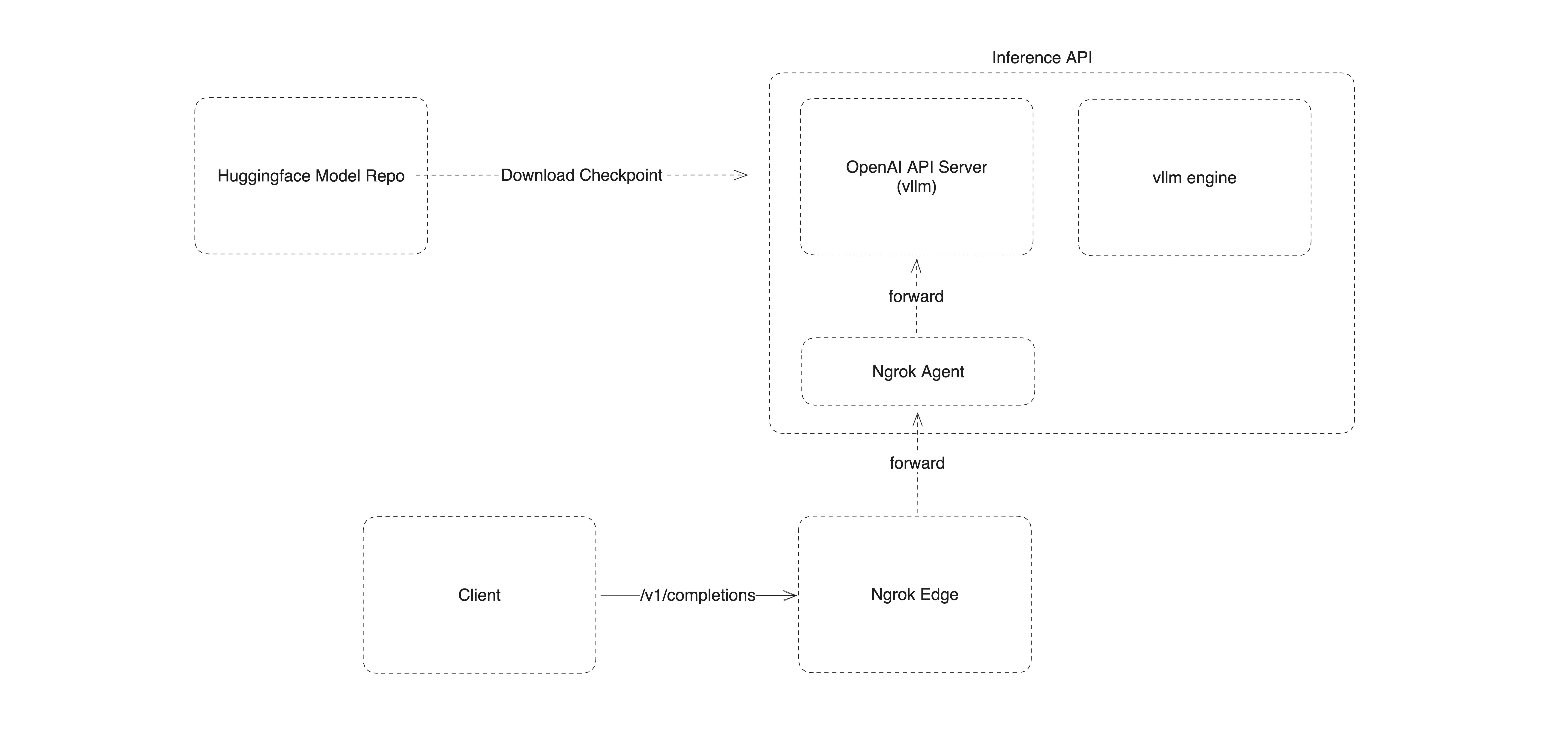
Special Note:
In this guide, we are using 2x T4 GPUs because vLLM doesn't support model quantization. We set --tensor-parallelism to 2, enabled by the underlying ray runtime.
1. Installing SkyPilot and Dependencies
System Requirements
- Python >= 3.7 (>= 3.8 for Apple Silicon)
- macOS >= 10.15 for Mac users
Step-by-Step Installation
- Create a new conda environment:
conda create -y -n sky python=3.8
conda activate sky
This creates and activates a new conda environment named
sky.
- Install SkyPilot:
pip install skypilot
We install SkyPilot from pip. You can choose other options based on the cloud service you are using.
- Install Optional Packages: (Optional)
# For AWS
pip install "skypilot[aws]"
# For Google Cloud
pip install "skypilot[gcp]"
These are optional installations depending on the cloud provider you are using.
- Cloud Account Setup:
For AWS:
pip install boto3
aws configure
For Google Cloud:
pip install google-api-python-client
conda install -c conda-forge google-cloud-sdk
gcloud init
Configure your cloud account credentials. This guide assumes you already have the appropriate permissions set up in your cloud account.
Troubleshooting and Notes
For Mac users with Apple Silicon, run the following command before installing SkyPilot:
pip uninstall grpcio; conda install -c conda-forge grpcio=1.43.0
2: Configure ngrok
Before deploying our model inference API server, we need to configure Ngrok so our endpoint will be accessible from the web. ngrok is a tool that creates a secure tunnel from the public internet to your local machine. But ngrok isn't just for simple tunneling; it also provides options for load balancing across multiple instances of your service. Here's how you can configure ngrok, get your Edge ID, and find your public URL:
From the Ngrok Docs on Load-Balancing:
Check out the Ngrok Guide for more detailed information!
Load Balancing with ngrok Cloud Edges
In the context of ngrok, 'edges' refer to the endpoints responsible for handling your incoming web traffic. If you plan on deploying your service across multiple servers, you'll benefit from setting up load balancing.
Setting up an HTTPS Edge
- Create an ngrok Account: If you haven't done this already, create an account on the ngrok website.
- Navigate to the Dashboard: Once logged in, go to the Cloud Edges page.
- Create a New Edge: Click the "+ New Edge" button and select "HTTPS Edge."
Upon completing these steps, you'll receive an HTTPS edge for serving web traffic and a public URL for accessing that traffic which will end up being your inference endpoint post-deployment.
3. SkyPilot Configuration YAML Explained
In your SkyPilot YAML, various configurations are set up to control the environment and execution of the model. Here is an explanation for each:
envs: Environment variables including the model name, Huggingface token, and ngrok settings.num_nodes: The number of nodes to deploy in the cluster.resources: Specifies the types of GPUs to use.setup: A series of commands to set up the environment. This includes activating the conda environment, installing required packages, and setting up ngrok.run: Commands that are run once the cluster is up. This starts the ngrok tunnel and the vLLM OpenAI API server.
envs:
MODEL_NAME: meta-llama/Llama-2-7b-chat-hf
HF_TOKEN: <Huggingface Token>
NGROK_TOKEN: <Ngrok Token>
NGROK_EDGE: <Ngrok Edge ID>
num_nodes: 1
resources:
accelerators: T4:2
setup: |
conda activate vllm
if [ $? -ne 0 ]; then
conda create -n vllm python=3.9 -y
conda activate vllm
fi
git clone https://github.com/vllm-project/vllm.git || true
# Install fschat and accelerate for chat completion
pip install fschat
pip install accelerate
cd vllm
pip list | grep vllm || pip install .
python -c "import huggingface_hub; huggingface_hub.login('${HF_TOKEN}')"
curl -s https://ngrok-agent.s3.amazonaws.com/ngrok.asc | sudo tee /etc/apt/trusted.gpg.d/ngrok.asc >/dev/null && echo "deb https://ngrok-agent.s3.amazonaws.com buster main" | sudo tee /etc/apt/sources.list.d/ngrok.list && sudo apt update && sudo apt install ngrok
ngrok config add-authtoken $NGROK_TOKEN
pip install ray pandas pyarrow
run: |
conda activate vllm
echo 'Starting ngrok...'
ngrok tunnel --label edge=$NGROK_EDGE http://localhost:8000 --log stdout > ngrok.log &
echo 'Starting vllm openai api server...'
python -m vllm.entrypoints.openai.api_server \
--model $MODEL_NAME --tokenizer hf-internal-testing/llama-tokenizer \
--host 0.0.0.0 \
--served-model-name llama-2-7b \
--tensor-parallel-size 2
4. Deploying Your SkyPilot Job
After writing your YAML configuration file, save it and run the following command to launch your job.
sky spot launch -n vllm vllm-api.yaml
Go have a ☕️, this might take a while!
In the background, SkyPilot will handle the heavy lifting. It will provision a relatively inexpensive CPU instance to manage spot jobs from and from there it will provision and set up your spot instance workload.
Expected Output
Upon successful deployment, you should see something like the following log messages:
(vllm, pid=14335) INFO: Started server process [19915]
(vllm, pid=14335) INFO: Waiting for application startup.
(vllm, pid=14335) INFO: Application startup complete.
(vllm, pid=14335) INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Troubleshooting
This is actually a little trickier to get right than we make it seem. In order to get things properly deployed, you will need to apply for quota increases in at least CPU and GPU allocation. The default nodes that are deployed in GCP require 8 CPUs and we'll need allocation for at least 2 Nvidia T4 GPUs (and more if you want to scale!).
Configuring your cloud accounts is out of scope of this post, but if you run into issues Intuitive Systems would love to help you out!
5. Using the Inference Endpoint
You can use the inference endpoint by replacing the openai.base_url in the OpenAI Python library. Here's how:
import openai
# Normally, you would initialize the OpenAI API client like this:
# openai.api_key = "your-api-key-here"
# To point to another endpoint, set the `api_base` parameter:
openai.api_base = "https://your-new-ngrok-edge-url.com"
# Now, when you make API calls, they will be directed to the new base URL
response = openai.Completion.create(
engine="llama-2-7b",
prompt="Translate the following English text to French: 'I love Large Language Models!'",
max_tokens=60
)
print(response.choices[0].text.strip())
5. Additional Resources and Next Steps
- To further explore, you should definitely check out the docs for each of the projects we talked about:
- SkyPilot
- vLLM
- Ray
- For more detailed commands and usage information, you should refer to the SkyPilot CLI reference.
By now, you should have a working setup for running your SkyPilot job with vLLM. Happy coding!
Conclusion
We've journeyed through the intricate landscape of Large Language Models, exploring the incredible advancements in technologies like SkyPilot, Ray, and vLLM that are changing the way we deploy, manage, and optimize these models. The leaps in scalability, cost-efficiency, and performance are revolutionary, but this is just the tip of the iceberg. The real power lies in applying these technologies to solve real-world problems, to streamline tedious tasks, and to amplify human capabilities.
Yet, even with all these advancements, navigating the complexities of LLMs can be daunting. This is where Intuitive Systems comes into play. As experts in the field of AI and ML, we are uniquely positioned to bring these technologies into your business processes. We don't just implement solutions; we customize them to fit your specific needs, ensuring that you get the most out of your investment.
Why Choose Intuitive Systems?
-
Expertise: With a deep understanding of technologies like SkyPilot, Ray, and vLLM, we are well-equipped to integrate advanced LLMs seamlessly into your existing infrastructure.
-
Customization: Every business is different, and we excel at tailoring our solutions to meet your unique requirements.
-
Scalability: Our solutions are built to scale, ensuring that as your business grows, your technology grows with it.
-
Cost-Efficiency: Through intelligent use of technologies like SkyPilot's cost-cutting features and vLLM's resource-efficient PagedAttention algorithm, we help you maximize ROI.
Your Next Steps
Imagine liberating your team from the tedious, time-consuming tasks that keep them from focusing on what truly matters. Consider the enormous potential of automating these processes with the power of cutting-edge LLMs. Now, realize that this future is just one call away.
Don't let the intricacies of these technologies deter you from revolutionizing your business processes. Allow us to handle the complexity so your human resources can get back to the work that truly matters.
Contact Intuitive Systems today, and let's build a smarter, more efficient future together.